
Karpathy投了一家AI记忆公司,撞名DeepSeek Engram记忆架构
Karpathy投了一家AI记忆公司,撞名DeepSeek Engram记忆架构当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?
来自主题: AI资讯
10612 点击 2026-06-24 16:02
 搜索
搜索
当大模型公司还在竞争更长的上下文窗口、更强的推理能力和更复杂的 Agent 工作流时,一家名为 Engram 的新公司选择押注另一个问题:AI 能不能像人一样,持续从每天接触到的资料、对话和经验中学习?
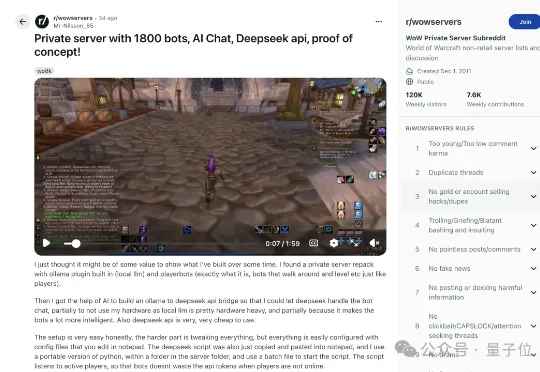
最近,一位Reddit老哥手搓了一个《魔兽世界》私服——里面活跃着1800个AI玩家,而且全都接入了DeepSeek API,能像真人一样聊天、组队、于是,暴风城的聊天频道突然变成了DeepSeek广场,画风大概是这样的:

斯坦福胡佛研究所追踪了 DeepSeek 七篇论文背后 356 名研究者的完整职业轨迹。美国培养出的最优秀 AI 人才正在大规模回流中国,而中国本土管道已经能独立产出前沿模型的核心贡献者。
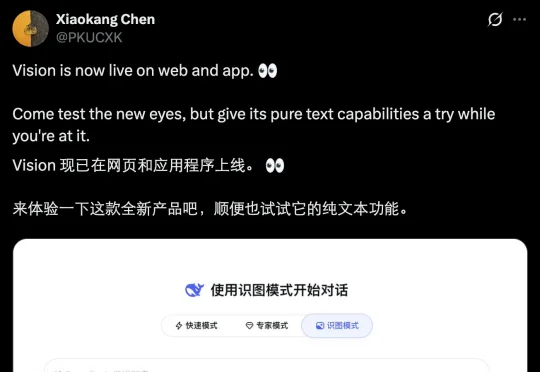
端午节前,DeepSeek 不出所料又有了新动作:官方平台全量推送了识图模式,手机端 App 也发布了更新,打开就能看到。此前,已经有不少网友体验过这个功能,但当时它还处在小范围的灰度测试阶段,只有部分用户能够在官方 App 或网页版里看到。但是今天下午,很多人都表示自己也能用了。

关于 DeepSeek 的融资信息,已经漫天遍野。已知信息,「elsewhere」不再赘述。以下,是我们了解到的一些未被展示过的故事或情节。先说那场投资人会议,也就是那个口耳相传的“四小时会议”。
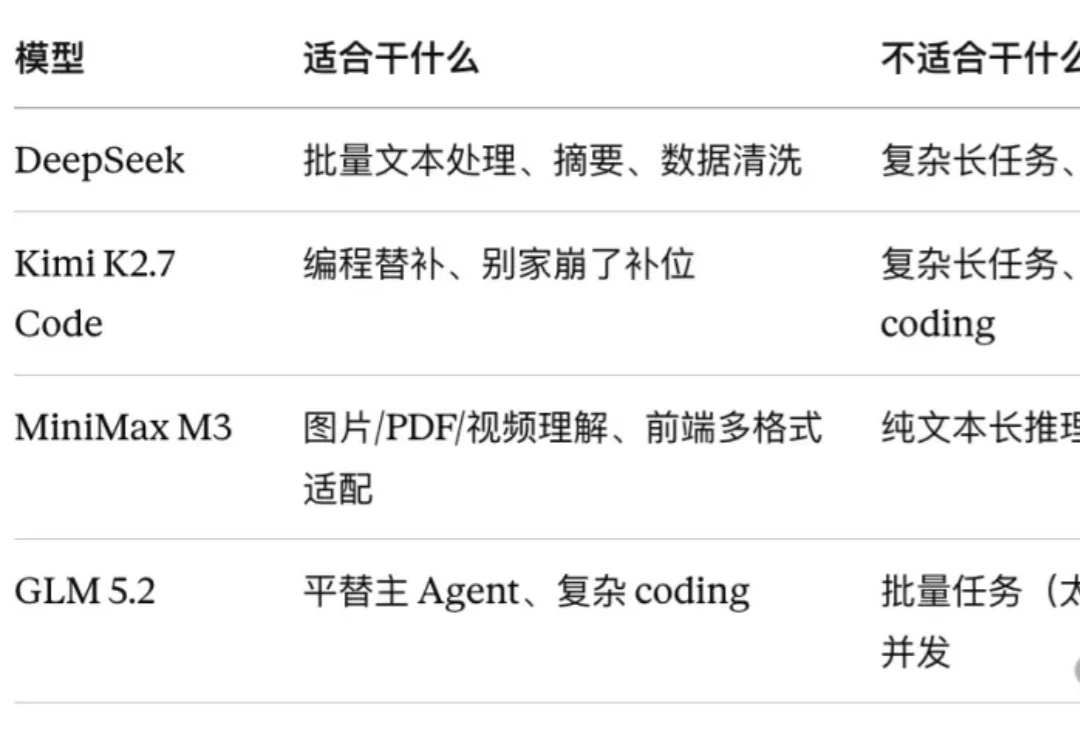
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。
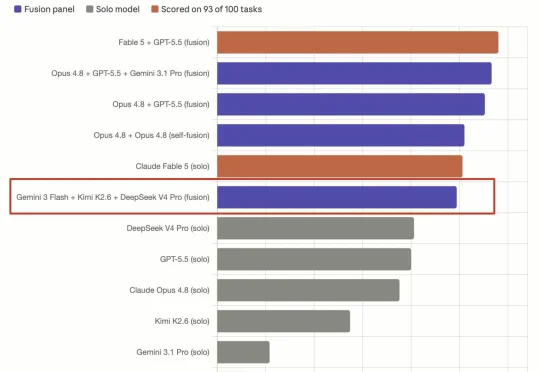
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。

过去一个多月,大模型圈依旧热闹。从 GPT-5.5、DeepSeek V4 到 Claude Opus 4.8,后训练正在成为模型能力提升的关键引擎。

近日,普林斯顿大学的研究团队发布了一篇新论文,提出了一个名为 Goedel-Architect 的智能体框架。他们用的核心模型,是国内开源大模型 DeepSeek-V4-Flash。

“AI新物种”企业级Token生产平台TokenBox™。